Anatomy of a Syscall
Long Long Road to Ring-0 and Back
Note: This blog is a product of what the kids call artisanal writing these days. The only use of AI was for grammar and spell checking.
What is a syscall? No... Really?
In Linux/Android land, a system call (syscall) is the controlled entry point from user space into kernel space. Whenever a user-space program needs the kernel to perform a privileged operation, such as reading a file, creating a process, allocating memory, or communicating with hardware, it must do so through a syscall.
Most devs encounter syscalls indirectly through familiar APIs such as read(), write(), and open(). These library functions eventually transition execution from user space into the kernel, where the requested operation is performed.
In this blog, we will dissect the read syscall from end to end. Along the way, we will also explore the common mechanisms shared by many Linux syscalls, the kernel objects they interact with, and why they matter to vulnerability researchers. It's a long, long road to ring-0 and back.
Wait... what actually happens when we call read()?
read() reads from an abstract byte stream. And since everything in Linux is "file-like", this byte stream could be: file, pipe, socket, procfs, sysfs entry, kernel virtual file. read is basically a libc wrapper, provided by glibc. Under the hood, the wrapper prepares the syscall arguments according to the architecture ABI (Application Binary Interface) and eventually executes a syscall instruction to enter the kernel.
can't we just yell at the kernel directly?
Technically, yes. Nothing stops you from bypassing libc and invoking the syscall instruction yourself. In fact, that's exactly what libc does on your behalf.
// this bypasses libc entirely
long ret;
__asm__ volatile (
"syscall"
: "=a"(ret)
: "0"(0), "D"(fd), "S"(buf), "d"(count)
: "rcx", "r11", "memory"
);This works. The kernel doesn't know or care whether the call came from glibc or your inline assembly. All it sees are register values.
libc: translator between two worlds
C library wrapper, for most cases, does nothing more than:
- place syscall arguments and the syscall number into the registers expected by the architecture ABI
- execute the architecture-specific syscall instruction, causing the CPU to transition into kernel mode
- set errno for any errors, after syscall has returned
libc exists because the syscall interface is raw, architecture-specific, and deliberately unstable. Syscall numbers differ between architectures, read is 0 on x86_64, 63 on ARM64. Argument registers differ. Error reporting differs, the kernel returns a negative errno in rax; libc translates that into the errno global your code actually checks. Older kernels exposed multiple variants of the same syscall (truncate vs truncate64) and libc quietly selects the right one.
so why do you exist, syscall?
CPU enforces privilege separation in hardware. On x86 and x86_64 processors, privilege separation is implemented using protection rings.
Ring 0 runs with the highest privilege and is typically where the kernel executes
Ring 3 is where ordinary user-space programs execute with significantly fewer permissions
CPU prevents Ring 3 code from:
- accessing kernel memory directly
- disabling interrupts
- modifying page tables
- executing privileged instructions
- jumping arbitrarily into kernel code
User-space jumping to an arbitrary kernel address is a big no no! Why? Because that's a recipe for instant kernel compromise. An attacker can jump past the security checks, enter mid-function, corrupt kernel state, fake stack layout, skip locking or forge execution context.
If user-space code could perform any of these operations directly, privilege separation would be meaningless. Syscalls exist as a tightly controlled gateway into kernel mode, allowing the kernel to validate requests before performing privileged work on behalf of a process.
knocking on ring-0's door
CPU needs a controlled privilege transition mechanism. Modern processors provide special entry mechanisms such as syscall, sysenter, interrupts, traps, exceptions, and svc on ARM. These gateways allow the processor to safely switch privilege levels, save execution state, and transfer control to trusted kernel entry points.
Everything discussed so far has been from an x86_64 perspective. On ARM64, the equivalent instruction is svc #0 (Supervisor Call). The syscall number is placed in x8, while arguments are passed through x0-x5.
When one of these entry mechanisms is invoked, the processor performs a tightly controlled sequence of operations:
- Transition from Ring 3 to Ring 0
- Switch to a kernel-controlled stack
- Save the user-space execution context
- Load a kernel-defined instruction pointer
- Begin execution at a predefined kernel entry point
The exact details differ across architectures and entry mechanisms, but the fundamental idea remains the same: user-space does not choose where execution continues in the kernel. The processor does.
The transition also carries information across the boundary. The syscall number identifies the requested operation, argument registers carry the inputs, and the processor preserves enough execution state for execution to eventually return to user-space.
who told the CPU where the kernel lives?
So, what happens FIRST when user-space executes
syscall?
The CPU itself performs part of the privilege transition before the kernel executes a single instruction. The syscall entry address is not hard-coded into every application; instead, the kernel programs a set of CPU registers known as Model Specific Registers (MSRs) during boot. Registers such as STAR and LSTAR tell the processor where execution should begin when a syscall instruction is executed.
Once the processor transfers control to the kernel entry point, Linux still needs to establish a usable execution environment. This is where concepts such as swapgs, per-CPU data, kernel stacks, and various mitigation mechanisms begin to appear.
Most of those details are beyond the scope of this blog, but one instruction is worth understanding.
why are we switching stacks?
Kernel cannot safely continue using user-space stack after entering Ring-0 because user-space is fully attacker controlled memory. If kernel keeps using it after privilege escalation to Ring-0, then kernel execution state would live inside untrusted memory.
...and what lives on the stack? registers, return addresses, local vars, func args, control-flow metadata, interrupt frames... you name it!
The stack IS the execution state!
User-space pages can be unmapped, paged out, made read-only, invalid, remapped concurrently. Therefore, CPU switches to a trusted kernel stack. On x86_64 Linux, each task has its own kernel stack. With the privilege transition complete and a trusted stack available, execution can continue through the kernel's syscall entry code.
On modern x86_64 systems, that journey begins in:
entry_SYSCALL_64 // (arch/x86/entry/entry_64.S)enter: swapgs
You are now executing in Ring 0. Great! But where is the current task? Where is the kernel stack? Where is the per-CPU data?
The kernel needs access to its own bookkeeping structures before it can do anything useful.
On x86_64, the GS segment register is commonly used as a fast pointer to thread-local or CPU-local data. While running in user-space, the GS base typically points at user-space thread-local storage. After entering the kernel, Linux needs %gs to point at kernel per-CPU data instead.
The swapgs instruction exchanges the current GS base with a kernel-controlled GS base configured by the OS.
After swapgs, references through %gs resolve into kernel per-CPU structures, what it retrieves is:
current- a pointer to the currently executing task (task_struct)- per-CPU data structs
- scheduler and CPU-local bookkeeping data
...very fast, without expensive lookups.
Before returning to user-space, Linux executes another swapgs to restore the original user-space GS base.
Many kernel subsystems rely on this mechanism. When you see code accessing data through %gs, it is often retrieving information about the currently executing CPU or task.
Fun fact: swapgs eventually found itself in the middle of the Spectre attack, leading to additional hardening and mitigation logic in modern syscall entry paths.
are you the oracle... kernel?
When user-space calls read(fd, buf, count); how does the kernel know which syscall was requested? where the args are? where execution should resume afterward?
- The kernel does not infer
read()from function name, that symbol is user-space/libc territory. Syscall number is stored in a predefined register,raxon x86_64 - Syscall ABI defines fixed argument registers,
rdi,rsi,rdx,r10,r8,r9, there is a reason they are written in that order, they are called/accessed in that order - CPU automatically saves user-space execution context during syscall:
RIP -> RCX
RFLAGS -> R11CPU then performs the controlled sequence of operations mentioned above. Later, kernel returns via sysret or iretq and execution resumes after the original syscall instruction.
the kernel's switch statement from hell
At this point, Linux has a valid execution context, a trusted kernel stack, and enough information to continue. You have crossed the boundary. The question now becomes:
How does the kernel know you asked for
read()?
Remember, the kernel never sees:
read(fd, buf, count);That symbol exists in user-space. By the time execution reaches the kernel, names are gone. All that remains is a syscall number and a handful of registers.
For read(), glibc eventually does something similar to:
mov rax, 0 ; __NR_read
mov rdi, fd
mov rsi, buf
mov rdx, count
syscallThe important part is:
mov rax, 0The kernel sees 0, not read().
When execution reaches do_syscall_64(), Linux uses the syscall number as an index into a giant dispatch table:
rax = 0 -> sys_call_table[0] -> __x64_sys_read()Think of it as the kernel's phone book. Every syscall number maps to a specific handler.
0 -> __x64_sys_read
1 -> __x64_sys_write
2 -> __x64_sys_open
...This is also why technologies such as seccomp, audit frameworks and syscall tracing operate on syscall numbers rather than function names. At the kernel boundary, names have already disappeared.
who the f*** are you?
You are finally executing kernel code. That does not mean the kernel trusts us.
Everything that arrived from user-space is treated as potentially hostile: syscall numbers, arguments, pointers, lengths, file descriptors... all of it.
Before Linux performs any real work, it constructs a well-defined kernel execution context and validates the incoming syscall state.
Only after this machinery is in place, you eventually reach:
entry_SYSCALL_64 -> do_syscall_64() -> sys_call_table -> __x64_sys_read() -> ksys_read()When __x64_sys_read() eventually receives fd, buf, and count, the kernel's default attitude is simple: "Assume this process is trying to kill me. Verify everything."
Why can't the kernel simply trust that
fd = 3means "open a file"?
The process maintains a file descriptor table:
0 -> stdin
1 -> stdout
2 -> stderr
3 -> struct file *
4 -> struct file *
...When user-space passes read(3, buf, 100); the kernel must map that integer to a live struct file object. An attacker can provide:
- negative file descriptors
- out-of-range descriptor numbers
- descriptors that have already been closed
- descriptors referring to unexpected object types
- descriptors that become invalid during concurrent execution
The key validation question is: "does this integer correspond to a live struct file that the process is allowed to use?"
the great dispatcher
Eventually you reach:
ksys_read() -> vfs_read() -> file->f_op->read_iter()Linux does not want every syscall to know which filesystem, socket, pipe, or device driver it is talking to.
Imagine if every read operation looked like:
if ext4 ...
if xfs ...
if pipe ...
if socket ...
if device ...That would be a maintenance nightmare. Instead, syscalls interact with the Virtual File System (VFS), which dispatches operations to the appropriate implementation.
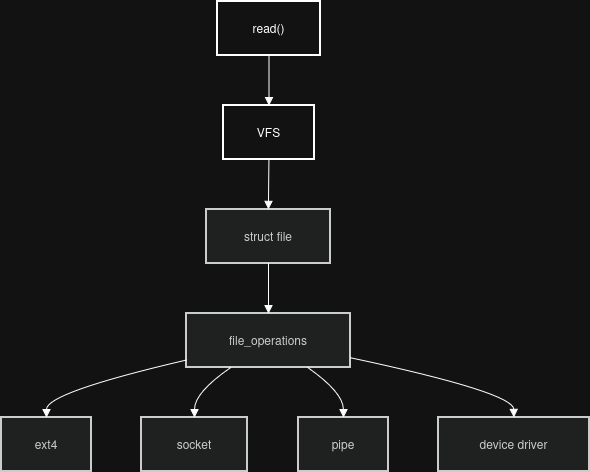
By this point, the file descriptor has already been resolved into a live struct file. A struct file contains fields such as:
f_pos- current file offsetf_flags- open flagsprivate_data- object-specific statef_op- file operations table
private_data is commonly used by drivers to store per-open-file state. When a driver's .open handler runs, it often allocates context and stores a pointer here.
The most interesting field here is f_op, which points to a file_operations structure. file_operations contains function pointers implementing operations such as read, write, mmap, poll, and ioctl.
Different objects install different handlers:
regular file -> ext4 handler
socket -> socket handler
pipe -> pipe handler
device -> driver handler
Eventually, VFS follows the function pointers stored in file_operations and reaches the object's actual read implementation, often through handlers such as read_iter().
The file_operations pointer lives in kernel memory. If you corrupt it, you control where .read dispatches.
The VFS doesn't know where the bytes come from. It only knows which handler to call.
From that point onward, every object follows its own path:
file -> page cache (or filesystem/disk on a cache miss)
pipe -> pipe buffer
socket -> network receive queue
procfs -> kernel-generated data
sysfs -> kernel-generated data
device -> driver-specific implementation
maybe we never touched disk
Most "reads" never touch the disk. When a process calls read(), the kernel does not immediately reach for the storage device. Instead, it first checks the page cache. If the requested data is already cached, the bytes are sitting in RAM and can be returned immediately.
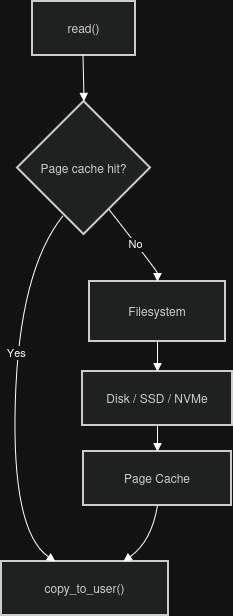
Only on a page cache miss does the kernel need to fetch data from storage. At that point, the request travels through the filesystem, down into the block layer, and eventually reaches the underlying storage device such as an HDD, SSD/NVMe drive.
The fetched pages are then inserted into the page cache so future reads can be serviced directly from memory.
touching enemy territory again
The kernel now has the bytes. But the problem is that those bytes live in kernel memory, while the caller expects them to appear in a user-space buffer:
read(fd, buf, count);That buf pointer came directly from user-space. Earlier in the syscall, you established a simple rule:
Assume the process is trying to kill us.
The kernel therefore cannot blindly write to that address. Instead, Linux uses helpers such as copy_to_user() to safely transfer data across the user-kernel boundary.
Before copying anything, the kernel must verify that the destination points to a valid user-space address. The supplied pointer may reference unmapped memory, inaccessible pages, or addresses that do not belong to the process at all.
Suppose:
buf = malloc(4096);The pointer returned by malloc() is a virtual address, not a physical one.
During copy_to_user(), the CPU's MMU translates this virtual address through the process's page tables to locate the corresponding physical page. If the mapping is valid, the copy proceeds. If the page is not present or the address is invalid, a page fault is generated and the kernel's fault handling machinery takes over. Only after these checks succeed can the bytes be copied from kernel memory into the caller's buffer.
This is where the page cache finally pays off. The bytes sitting in kernel memory are copied into the caller's buffer, making them visible to the process that originally requested them.
your syscall may take a nap
Up until now, your journey has looked deceptively simple. A process calls read(), enters the kernel, retrieves some bytes, and returns to user-space. Reality is often messier.
A syscall is not necessarily a straight, uninterrupted path.
Your process may sleep while waiting for disk I/O, waiting for data to arrive through a pipe, or waiting for network data to appear on a socket. At some later point, it will be resumed and continue executing the same syscall.
While all of this is happening, the rest of the system keeps moving. Interrupts occur, other processes run, disk requests complete, network packets arrive, timers expire, and scheduler decisions are made.
From the process's perspective, however, none of this complexity is visible. Once awakened, execution simply continues from where it left off.
mission accomplished?
If everything succeeds, the kernel returns the number of bytes read:
return 128;If something goes wrong, the kernel returns a negative error code:
return -EFAULT; // invalid user-space buffer
return -EBADF; // invalid file descriptorAn invalid file descriptor? -EBADF A bad user-space pointer? -EFAULT
Permission problems, interrupted operations, missing files, unsupported operations... all eventually become error codes returned back up the call chain.
By the time execution leaves ksys_read(), the kernel has reduced an enormous amount of complexity into a single value: either the number of bytes read, or a reason why the operation failed.
the long road home! (^_^)
The kernel now restores the user-space execution context from the state saved during syscall entry: instruction pointer, stack pointer, processor flags, and other architectural state.
Eventually, execution reaches:
sysretThe CPU performs the reverse privilege transition and returns from Ring 0 back to Ring 3.
From the process's perspective, the journey is invisible. Execution simply resumes at the instruction immediately following the original syscall, with the return value waiting in rax.
What began as:
read(fd, buf, count);has traveled through privilege transitions, kernel entry code, syscall dispatch, VFS, kernel objects, page cache, memory management, and scheduler reality before finally returning to user-space.
It's a long, long road to ring-0 and back.